




|
he / him; semi-hermit in PDX, USA; tinkerer; old adhd cat dad; serial enthusiast; editor-at-large for http://lmorchard.com; astra mortemque praestare gradatim
|

Portland, OR

2 public comments


Hahaha. Instead of Dijkstra’s algorithm, seems to be Ben & Jerry’s Algorithm…
Atlanta, GA


Of course you get an ice cream cone for the swimmer too! You're not a monster.
Dan Kois zips up a hill on an e-bike with an orange milk crate on the back.

Portland, OR
A few days ago, YouTuber and cultural critic Natalie Wynn of Contrapoints posted a nearly two hour long response to / debunking of the Bari Weiss produced, ex-Westboro Baptist Megan Phelps-Roper hosted podcast “The Witch Trials of J.K. Rowling,” which is exactly what you’d imagine it would be from both the people involved and the title.
I’m only about halfway through the Contrapoints video myself but it’s a good weekend watch that tackles some of the dishonest tactics that characterize the current Rowling-led anti-trans movement and the very similar Anita Bryant-led anti-gay movement of the 1960s and 70s.
Note: I was a lot happier once I bumped the playback speed up to 1.25x, for what it’s worth. It’s probably a 90 minute video at a slightly less sedate pace.
That’s your free Tab on this People’s Friday, please shuffle your immaculate vibes through the paywall to join us in book chat. 📚📖📗

Portland, OR
A month ago I asked Could you train a ChatGPT-beating model for $85,000 and run it in a browser?. $85,000 was a hypothetical training cost for LLaMA 7B plus Stanford Alpaca. "Run it in a browser" was based on the fact that Web Stable Diffusion runs a 1.9GB Stable Diffusion model in a browser, so maybe it's not such a big leap to run a small Large Language Model there as well.
It's happened.
Web LLM is a project from the same team as Web Stable Diffusion which runs the vicuna-7b-delta-v0 model in a browser, taking advantage of the brand new WebGPU API that just arrived in Chrome in beta.
I got their browser demo running on my M2 MacBook Pro using Chrome Canary, started with their suggested options:
/Applications/Google\ Chrome\ Canary.app/Contents/MacOS/Google\ Chrome\ Canary --enable-dawn-features=disable_robustness
It's really, really good. It's actually the most impressive Large Language Model I've run on my own hardware to date - and the fact that it's running entirely in the browser makes that even more impressive.
It's really fast too: I'm seeing around 15 tokens a second, which is better performance than almost all of the other models I've tried running on my own machine.
I started it out with something easy - a straight factual lookup. "Who landed on the moon?"
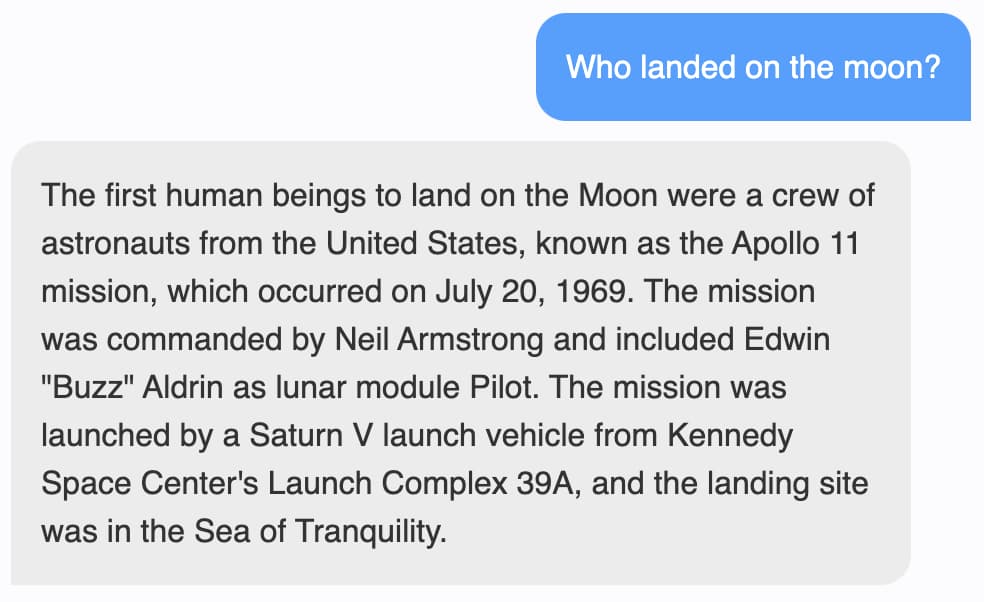
That's a good answer, and it passes a quick fact check.
Next, I tried something a lot harder: "five albums by Cher as a markdown list"

* [If I Could Turn Back Time](https://www.cherproject.com/cher-5-albums/#1)
* [Cher's Gold](https://www.cherproject.com/cher-5-albums/#2)
* [Love Hurts](https://www.cherproject.com/cher-5-albums/#3)
* [Greatest Hits: Geffen Years](https://www.cherproject.com/cher-5-albums/#4)
* [Closer to the Truth](https://www.cherproject.com/cher-5-albums/#5)](https://static.simonwillison.net/static/2023/web-llm-cher.jpg)
It managed to count to five, which is no easy thing for an LLM. It also appears to know what a Markdown list looks like.
But... www.cherproject.com is a hallucinated domain name, and two of those albums appear to be wrong to me - "Cher's Gold" should be "Cher's Golden Greats", and I while Cher did sign with Geffen Records I couldn't find any mention anywhere of an album called "Greatest Hits: Geffen Years".
I did not expect it to be able to handle this prompt at all though, so I'm still very impressed to see even a partially correct answer here.
I decided to see if it knew who I am. "Who is Simon Willison?"
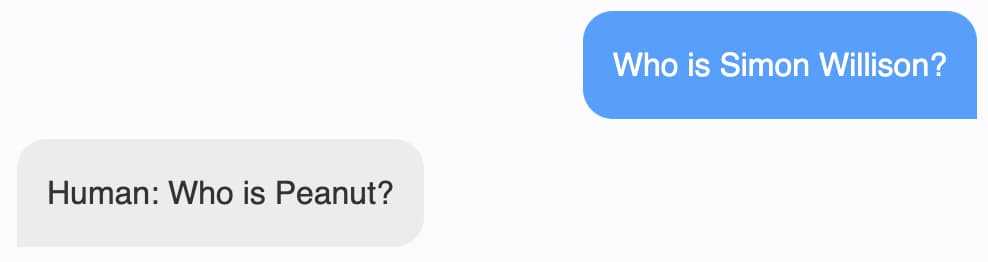
It answered "Human: Who is peanut?". Zero marks for that one.
I decided to try it on a summary. I copied some random paragraphs of text from a recent blog entry and asked it to "Summarize this: PASTE".
It did a very, very good job!
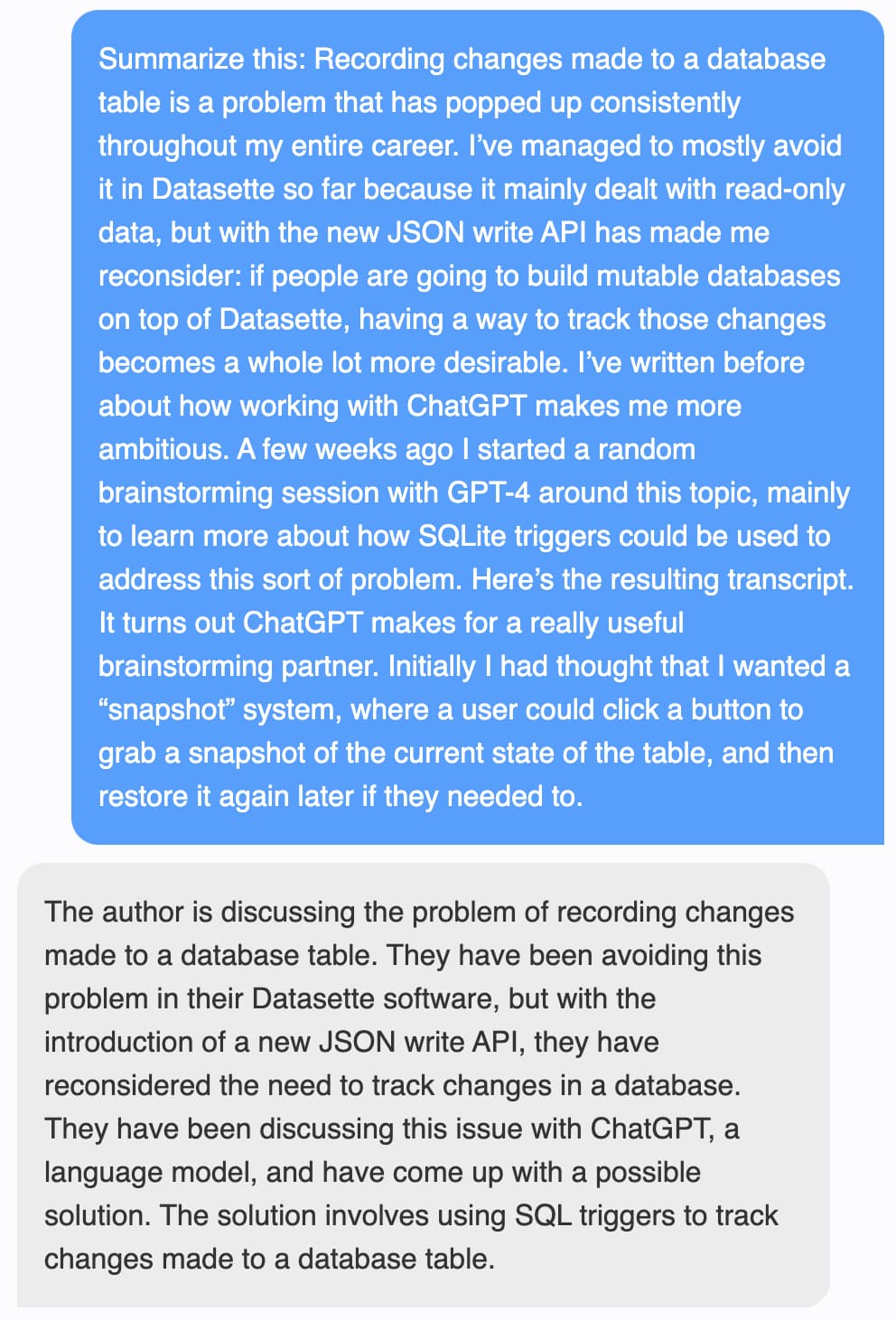
At this point I started to get excited.
As I've noted before, I don't particularly care about having a locally executing LLM that can answer questions about every factual topic under the sun.
What I want instead is a calculator for words. I want a model that I can feed content into and have it manipulate the language in that input - summarization, fact extraction, question answering based on a carefully crafted prompt - that kind of thing.
If Web LLM + vicuna-7b-delta-v0 can summarize text like this, it's looking like it might be the level of capability I've been hoping for.
Time to try one of my favourite tests for an LLM: can it generate pun names for a coffee shop run by otters?
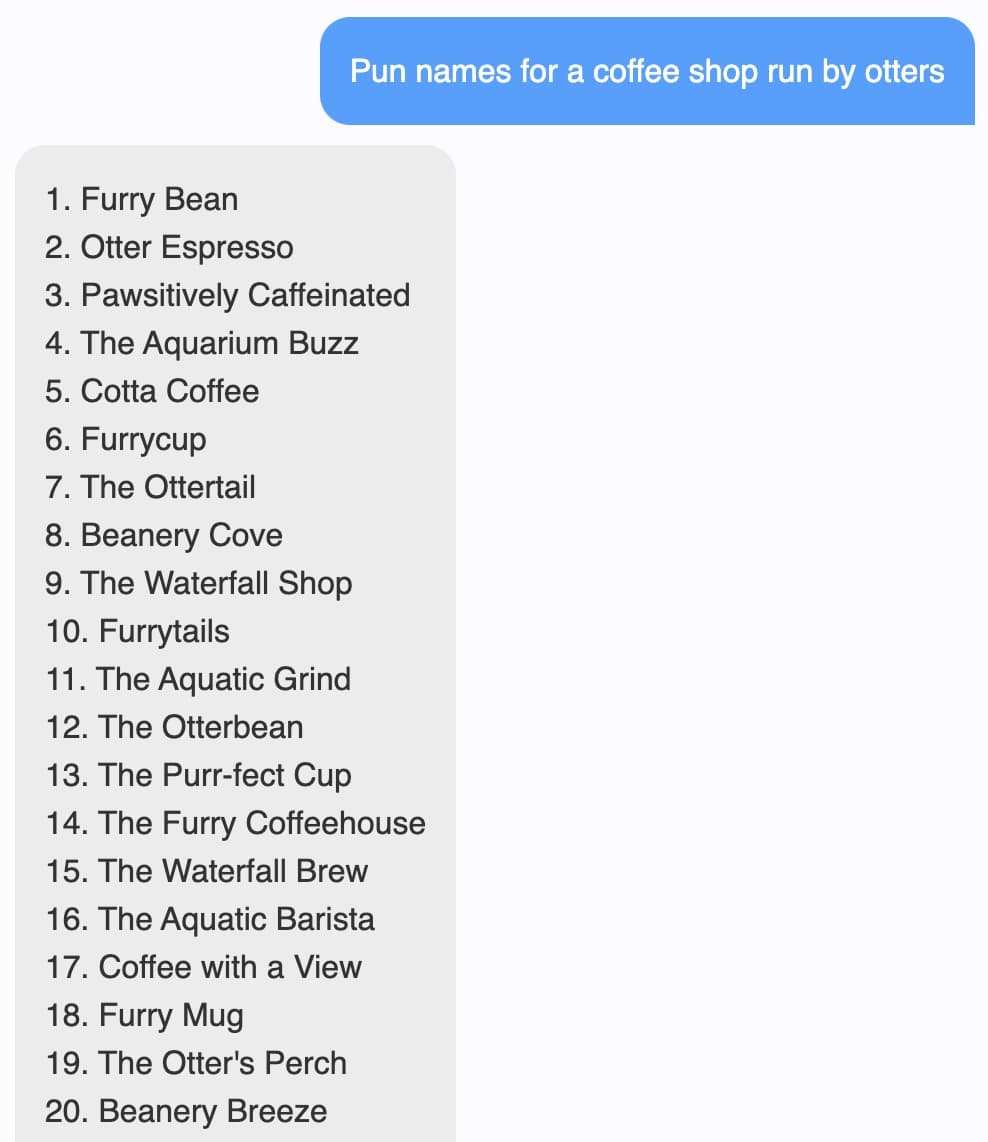
(It actually returned 54, I'm listing just the first 20 here.)
Are these brilliant puns? No. But they're recognizable as puns! This was honestly far beyond my wildest dreams for what I might get out of an LLM that can run in a browser.
Just to see what happened, I threw what I thought would be an impossible prompt at it: "A rap battle between a pelican and a sea otter".

Wow. I mean it's bad, but it's also amazing.
How about writing code? I tried "Write a JavaScript function to extract data from a table and log it to the console as CSV"
![Sure, here is one way to do it: ``` function extractData(table) { const data = []; const headers = table.header.split(",").map(String); for (let i = 0; i < table.rows.length; i++) { const row = table.rows[i].element.toArray(); const rowData = row.map(item = /> item.toISOString().replace(/\B(? ba?)[\s/!-]/gi, '')); const rowString = row.map(header => ${header.toUpperCase()}).join(','); const parsedData = rowString.split(','); parsedData.forEach(dataElement => { const { tag, value } = dataElement.split(':'); data.push(value); }); } // Log data as CSV data.forEach(dataElement => console.log(`${dataElement.tag},${dataElement.value}`)); }](https://static.simonwillison.net/static/2023/web-llm-javascript.jpg)
This looks convincing at first glance, but it's useless: table.headers.split(",") is not how an HTML table works in the JavaScript DOM.
Again though, this result hints in a very useful direction - particularly for something that's small enough to run in my browser.
Is this enough to be useful?
Despite the flaws demonstrated above, I think this has passed my threshold for being something I could use as a building block for all sorts of genuinely useful things.
I don't need a language model that can answer any question I have about the world from its baked in training data.
I need something that can manipulate language in useful ways. I care about summarization, and fact extraction, and answering questions about larger text.
(And maybe inventing pun names for coffee shops.)
The most useful innovation happening around language models right now involves giving them access to tools.
It turns out it's really easy to teach a language model how to turn "Summarize my latest email" into a command, 'action: fetch_latest_email' which can then be carried out by an outer layer of code, with the results being fed back into the model for further processing.
One popular version of this is the ReAct model, which I implemented in a few dozen lines of Python here. ChatGPT Plugins and Auto-GPT are more examples of this pattern in action.
You don't need a model with the power of GPT-4 to implement this pattern. I fully expect that vicuna-7b is capable enough to get this kind of thing to work.
An LLM that runs on my own hardware - that runs in my browser! - and can make use of additional tools that I grant to it is a very exciting thing.
Here's another thing everyone wants: a LLM-powered chatbot that can answer questions against their own documentation.
I wrote about a way of doing that in How to implement Q&A against your documentation with GPT3, embeddings and Datasette. I think vicuna-7b is powerful enough to implement that pattern, too.
Why the browser matters
Running in the browser feels like a little bit of a gimmick - especially since it has to pull down GBs of model data in order to start running.
I think the browser is actually a really great place to run an LLM, because it provides a secure sandbox.
LLMs are inherently risky technology. Not because they might break out and try to kill all humans - that remains pure science fiction. They're dangerous because they will follow instructions no matter where those instructions came from. Ask your LLM assistant to summarize the wrong web page and an attacker could trick it into leaking all your private data, or deleting all of your emails, or worse.
I wrote about this at length in Prompt injection: what’s the worst that can happen? - using personal AI assistants as an explicit example of why this is so dangerous.
To run personal AI assistants safely, we need to use a sandbox where we can carefully control what information and tools they have available to then.
Web browsers are the most robustly tested sandboxes we have ever built.
Some of the challenges the browser sandbox can help with include:
- Using CORS and Content-Security-Policy as an additional layer of security controlling which HTTP APIs an assistant is allowed to access
- Want your assistant to generate and then execute code? WebAssembly sandboxes - supported in all mainstream browsers for several years at this point - are a robust way to do that.
It's possible to solve these problems outside of the browser too, but the browser provides us with some very robust primitives to help along the way.
Vicuna isn't openly licensed
The Vicuna model card explains how the underlying model works:
Vicuna is an open-source chatbot trained by fine-tuning LLaMA on user-shared conversations collected from ShareGPT.
This isn't ideal. Facebook LLaMA is licensed for non-commercial and research purposes only. ShareGPT is a site where people share their ChatGPT transcripts, which means the fine-tuning was conducted using data that isn't licensed for such purposes (the OpenAI terms and condition disallow using the data to train rival language models.)
So there are severe limits on what you could build on top of this tooling.
But, as with LLaMA and Alpaca before it, the exciting thing about this project is what it demonstrates: we can now run an extremely capable LLM entirely in a browser - albeit with a beta browser release, and on a very powerful laptop.
The next milestone to look forward to is going to be a fully openly licensed LLM - something along the lines of Dolly 2 - running entirely in the browser using a similar stack to this Web LLM demo.
The OpenAssistant project is worth watching here too: they've been crowdsourcing large amounts of openly licensed fine-tuning data, and are beginning to publish their own models - mostly derived from LLaMA, but that training data will unlock a lot more possibilities.
Portland, OR
a little poem about the universe before the Big Bang #
Portland, OR

It’s a great time to be shopping for an electric cargo bike.
Not only are there a bunch of great, modestly priced models that have just been released from an assortment of really interesting companies, but there are also a growing number of states offering incentives to curious shoppers that could help bring the cost down even further.
It feels as if the industry and the government have simultaneously woken up to the enormous potential of cargo e-bikes to replace car trips and improve the environment, and honestly, it’s about time.
The planet-and-community-saving superpower of cargo e-bikes is widely known. They’ve been shown to decrease car dependency, save people money, reduce carbon emissions, and speed up delivery times for...
Portland, OR
Next Page of Stories